
Cuando uno se adentra en el universo del comercio, una de las dificultades más grandes que se encuentra es con el hecho de cómo obtener los datos de comercio exterior de los países de una manera sencilla, rápida y con pocas líneas de programación.
Cuando uno inicia, normalmente va a los sitios que tienen información dipsonible y con unos clicks encuentra lo que busca, pero esto sólo es el inicio. Páginas como www.trademap.org o https://dataweb.usitc.gov/ (Estados Unidos), DataComex de España (https://datacomex.comercio.es/, son geniales, pero estos datos normalmente están agregados y con un detalle que permite realizar análisis muy a nivel top.
Las importaciones y exportaciones nos dan una idea económicamente de cómo se están comportando los mercados, se podría hablar de un tamaño de mercado de importaciones (que incluye lo que va directamente al consumidor final o a una industria, por ejemplo rosas o azúcar para el sector industrial). El detalle de las estadísticas ha cambiado tanto en los últimos años, que nos permite una granularidad que antes no se tenía, lo cual permite analizar los mercados y hacer estimaciones. El comercio cada vez es un motor de crecimiento para los países, si es como cualquier variable económica bien manejado, es decir hay equilibrios.
En este artículo, utilizaré a Estados Unidos, como el mejor ejemplo de cómo obtener datos de una forma rápida, sencilla y directa. No complicaciones, sólo unas líneas de código en Python y tienen las estadísticas de comercio exterior que si se utilizaran las vías normales, tomaría varias horas si no días en hacerse. Para mayor información del funcionamiento del API visitar: https://www.census.gov/data/developers/data-sets/international-trade.html
Paso 1:
Instalar las librerías necesarias, para este caso usaremos pandas, requests y json. De no tenerlas, usar:
!pip install pandas requests json
Paso 2:
Una vez instaladas las librerías, vamos a crear la llamada (API) para descargar los datos. Por ejemplo, si quiero descargar la información del capítulo 15 del Sistema Armonizado (Aceites, en general), vamos a usar la siguiente estructura:
df = pd.read_json ('https://api.census.gov/data/timeseries/intltrade/imports/hs?get=CTY_CODE,CTY_NAME,I_COMMODITY,I_COMMODITY_LDESC,I_COMMODITY_SDESC,
GEN_VAL_MO,GEN_QY1_MO,UNIT_QY1&time=from+2017-01+to+2024-02&COMM_LVL=HS10&I_COMMODITY=15*')
Ahora iremos paso a paso en lo que significa cada parte del requerimiento:
a. api.census.gov/data/timeseries/intltrade/imports equivale a la dirección que se ha especificado para acceder a los datos de “importaciones”, si se quisiera exportaciones, se cambia a “exports”, lo que hace es ir a un folder directo en el servidor de comercio de Estados Unidos. Esto viene del documento del API del Census Bureau (es bueno leerlo).
b. La segunda parte es la más importante (hay reglas que seguir):
-
- hs?get: significa que obtendrá los datos a nivel de inciso arancelario (sistema armonizado)
-
- CTY_CODE: código de los países de acuerdo con el sistema de Estados Unidos
-
- CTY_NAME: nombre del país y AGRUPACIONES DE PAÍSES (en algunos requerimientos es necesario que estén los dos para que funcione)
-
- I_COMMODITY: son los 10 dígitos que identifican al producto (inciso arancelario, es el código a nivel internacional que es reconocido, todos los países tienen igualdad de descripciones hasta 6)
-
- I_COMMODITY_SDESC: nombre “corto” de la descripción del producto (en términos de comercio, es la descripción que tiene en el sistema armonizado)
-
- I_COMMODITY_LDESC: nombre largo y completo de la descripción del producto
-
- GEN_VAL_MO: es el valor mensual en US$ (USD), es mejor que sea mensual y no totales, Excel, Tableau, PowerBi, Qlik, manejan de mejor manera las fechas mensuales.
-
- GEN_QY1_MO: es el valor mensual en la unidad de medida acordada internacionalmente para este tipo de productos (depende de cada producto), pero generalmente son kilos
-
- UNIT_QY1: indica que tipo de medida es, para aquellos que están interesados más en volumen y no valor
-
- time=from+2017–01+to+2025–08: es el rango de fechas que se quieren descargar (lo más antiguo 2013, pero tiene limitaciones de descarga, puede haber error). En este caso es desde enero 2017 a la última fecha conocida que hay información (agosto 2025). Depende del usuario, es modificable.
-
- COMM_LVL=HS10: nivel máximo de desagregación, en este caso se llega al nivel de granularidad más amplio. Si se quiere sólo el capítulo por ejemplo sería HS2 y así sucesivamente, en números pares (4,6,10)
-
- I_COMMODITY=15*: es el capítulo que deseo descargar (va desde el 01 hasta el 97). En este caso es aceites, para una lista comprensiva de qué es cada capítulo ver: https://hts.usitc.gov/
En este caso descargué las importaciones de grasas y aceites animales o vegetales y sus productos de desdoblamiento; grasas comestibles preparadas; ceras animales o vegetales de Estados Unidos, desde enero del 2017 a agosto del 2025. UN TOTAL DE 210,989 registros, con una duración estimada de 3m 13s.
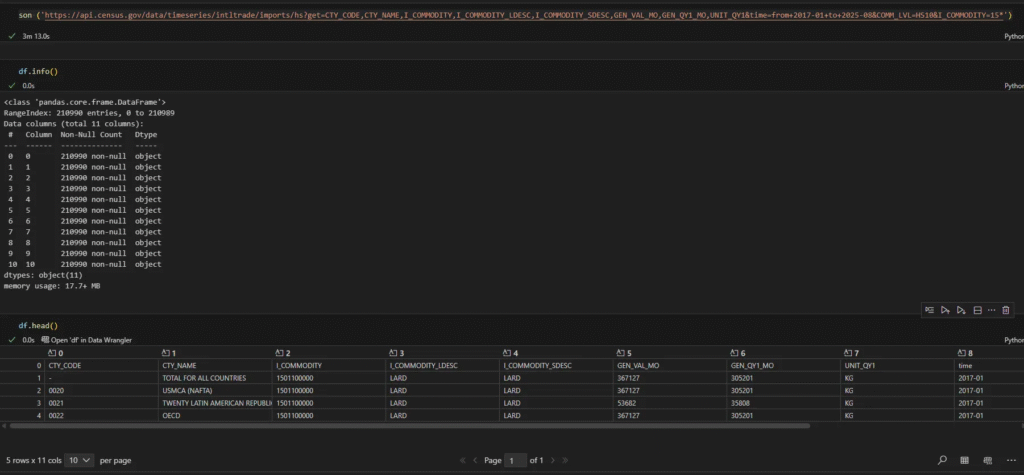
Un poco de limpieza para que realmente quede de la mejor manera para exportar para uso posterior. Generalmente se usa csv debido al tamaño de los archivos, pero en este caso como son menos del millón de filas que soporta Excel, se hará también una exportación en este formato.
#Cleaning and renaming columns / Limpiando y renombrando columnas
df=df.drop(df.columns[[0,10]], axis=1) #droping unwanted columns if any / bota filas no deseadas si las hay
new_header = df.iloc[0] #grab the first row for the header / usa el nombre de la primera fila como encabezado
df = df[1:] #take the data less the header row / toma los datos menos la fila del encabezado
df.columns = new_header #set the header row as the df header / establece la fila del encabezado como el encabezado del df
df.rename(columns={«I_COMMODITY»: ‘Inciso’, «I_COMMODITY_SDESC»:»Descripción corta», «I_COMMODITY_LDESC»: ‘Descripción’, ‘GEN_QY1_MO’:’Volumen’,’UNIT_QY1′:’Unidad’,’GEN_VAL_MO’: ‘Valor US$’, «time»: «Fecha», ‘CTY_NAME’: ‘País’}, inplace=True) #renaming columns / renombrando columnas
df.head()
df.to_excel(‘Imports_HS10_15_2017-2025.xlsx’, index=False) # cambiar a su dirección / change to your destination folder
#Cambiar valores a numéricos y fecha
df[«Valor US$»] = pd.to_numeric(df[«Valor US$»], errors=’coerce’)
df[‘Volumen’] = pd.to_numeric(df[‘Volumen’], errors=’coerce’)
df[‘Fecha’] = pd.to_datetime(df[‘Fecha’]).dt.date
El resultado final del archivo de Excel se verá así:

Un resumen de los datos en tabla dinámica para poder corroborar que están bien versus lo descargado manualmente (ver imagen):

Para corroborar que lo anterior funcionó, adjunto extracto del resultado obtenido utilizando la forma tradicional o si quieren el archivo de Excel o el script completo, pueden solicitarlo a rodolfomerida@msonigt.com

Con esto ya se tiene todo listo para hacer cualquier análisis, el script, completo no debe de tardar más de 5 minutos.
Escríbanos, y compruebe la rapidez de nuestros servicios.
Rodolfo Mérida

