
El comercio exterior de España, provincia por provincia: inteligencia comercial de una década, lista para decisiones reales
España es una de las economías más importantes en Europa. Los datos tradicionales que se obtienen de las plataformas sólo dan las cifras totales y obtener la granularidad de qué provincia importa o exporta qué, es una tarea titánica.
Inicié de la forma tradicional con Pandas, pero cada año de comercio mensual implicaba 3.5 gigas al cual había que hacerle modificaciones importantes en el proceso (agregar nombre de países, nombre de productos, provincias, cambiar formato).
El año se transformaba en más de 15 gigas de RAM que la memoria tenía que usar, si lo deseaba hacer anual. Usé dask para acelerar el proceso y tampoco. Luego decidí partirlo por trimestre, pero al final cuando necesitaba computarlo a una sola base sucedía lo mismo, sistema sin memoria. La pregunta era qué hago si tengo más años. Use https://lightning.ai/ que daba créditos y disponía de 250 Gigas de RAM pero rápidamente los utilizaba y posterior había que pagar. Pagué Google Colab para hacer el primer ejercicio y consolidar los primeros años.
Recién pregunté a Google Gemini, qué camino podíamos usar y le compartí mi notebook. Me sugirió DuckDb -nunca lo había usado- así que dejé que conjuntamente llevaramos el proceso. El resultado, logré consolidar la base de comercio exterior del 2015 al 2025 (noviembre). Más de 40 gigas de información, con una computadora que tiene 64 de RAM (no todo disponible para este proceso). También he leído recientemente un artículo publicado por Modexa https://medium.com/@Modexa/duckdb-for-mlops-faster-data-prep-without-the-drama-940dcdbad86f que habla del uso de este tipo de base de datos.
La pregunta era, al final, si después de todo este esfuerzo, si la base y los datos estaban bien. El resultado: SI.
Entonces..¿qué provincia compra más del mundo de España y qué producto es?
El comercio total de España para el 2025 fue de de €809.2 mil millones de euros. De estos las importaciones, €424.7 mil millones -53% aprox-. Estos datos son los que obtendríamos de plataformas que están generalmente de libre acceso, dan datos agregados de los totales para todo, lo que al día de hoy carece de significado y relevancia para las empresas.
Decir que creció o que se importó es de mucho valor para las pequeñas y medianas empresas, que desde países más pequeños traten de identificar las oportunidades existentes comercialmente. El comercio hace que crezcan los países dice la teoría, pero en la práctica es mucho más complejo.
Primera pregunta: ¿Qué provincia importó más en el 2024?
Barcelona. Madrid. Valencia. Zaragoza. Tarragona. Son las 5 provincias que importan más €240.0 mil millones de euros (cerca del 56.1%). Pero hay diferencias importantes. Entre el segundo y el tercero, es tres veces más grande el segundo. Con esto se empieza a visulmbrar las características económicas de España. Uno pensaría: entremos en estas provincias, busquemos clientes. Pero son complejas, difíciles.
Importaciones de España Acumuladas 2015-Oct. 2025, Valores en Miles de Millones (B) y en € (euros)
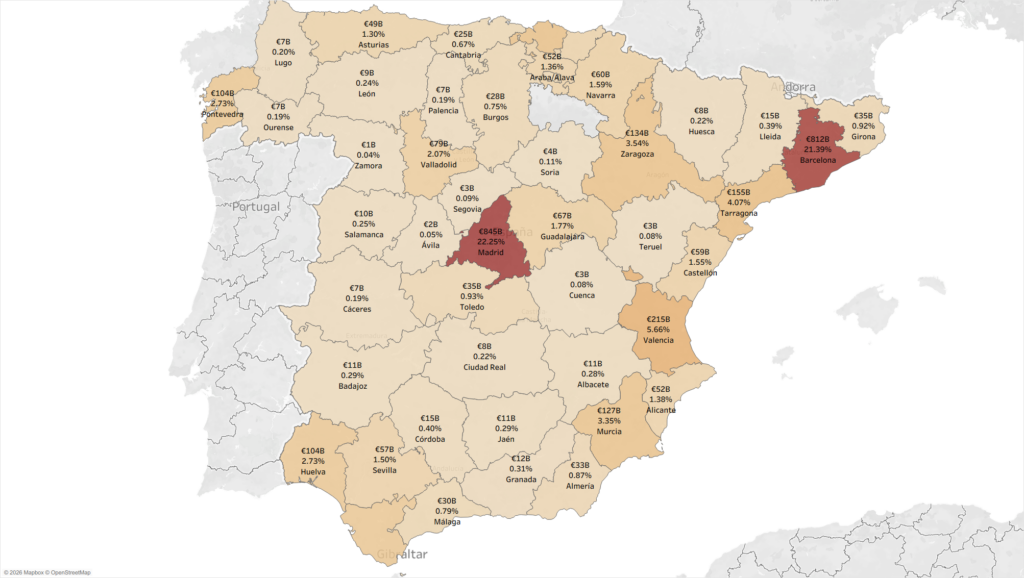
Fuente: Elaboración propia sobre la base de datos de DataComex.
Segunda pregunta: ¿Quién crece más?
No sólo importa el volumen, sino también quién crece más. Indica dinamismo. Para evitarme fluctuaciones anuales, use el CAGR (2015–2024, que da un crecimiento anual entre las fechas, similar a una inversión). Los resultados cambiaron.
Cuenca. Toledo. Segovia. Cáceres. Córdoba. Estos son los que crecen más, entre dos y tres veces más que las importaciones totales.
Crecimiento (CAGR 2015–2024), provincias de España. €.
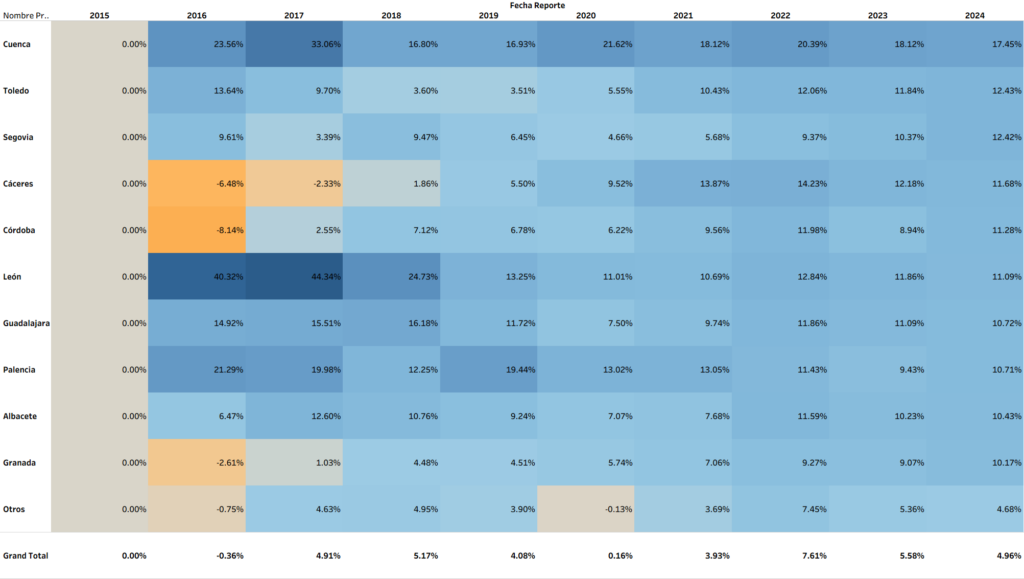
Fuente: Elaboración propia sobre la base de datos de DataComex.
Tercera pregunta: ¿Qué compran más Barcelona y Madrid? Y se podría responder a cada una de las provincias…
Madrid
- Principalmente: Medicamentos, gas natural, productos inmunológicos, energía eléctrica, teléfonos móviles, todos industriales.
- Productos agrícolas: Tabaco, envaes, cereales, carne de bovinos, cigarros, café, agua, salmones del atlántico.
Barcelona:
- Vehículos, medicamentos, gas natural, hidrógeno, carborreactores.
- Productos agrícolas: soya, café, aceites, cacao, cereales (maíz), entre otros.
Y así sucesivamente podríamos saber de cada una de las provincias de España.
Cuarta pregunta: ¿De dónde vienen?
Madrid
- Alemania (13%), China (12%), Estados Unidos (10%), Francia (10%), Italia (7%).
Barcelona
- Alemania (17%), China (13%), Francia (9%), Italia (8%), Países Bajos (4%), Estados Unidos (3%).
Y así sucesivamente podemos ir desagregando la información hasta llegar a un nivel detallado.
Conclusión:
Si hubiera seguido el camino tradicional, no habría terminado este proyecto sin pagar. Con DuckDB lo logré en una semana — un análisis que llevaba más de dos años queriendo completar.
Aprendiendo. Arriesgando. Concluyendo.
Este ejercicio me dio información granular para identificar oportunidades reales de comercio exterior. Y eso es precisamente lo que hacemos: analizamos datos como estos para encontrar dónde están las oportunidades comerciales.
Para conectar esas oportunidades con contactos y proveedores reales, trabajamos con plataformas como TradeAtlas.
Si tu empresa busca oportunidades de comercio exterior, conversemos en rodolfomerida@formato4.com o manda un mensaje.
—–
Este fue el código final utilizando DuckDb, que hizo lo posible, correr desde mi computadora, sin pagar nada más, esta base de datos:
#Consolidar todos los archivos nuevos de forma incremental
import duckdb
import time
import glob
import os
import pandas as pd
# --- CONFIGURATION ---
# Point to the PARENT folder containing year folders (2015, 2016, etc.)
ROOT_PATH = r"G:\Bases\España\Datos"
CATALOG_PATH = r"G:\Bases\España\Datos\Catalogos"
DB_FILE = "trade_database.duckdb"
FINAL_OUTPUT = "consolidated_trade_history.parquet"
def fix_path(path):
return path.replace('\\', '/')
def run_production_pipeline():
con = duckdb.connect(DB_FILE)
print("🚀 Starting Production Pipeline...")
# ---------------------------------------------------------
# 1. SETUP & HISTORY TRACKING
# ---------------------------------------------------------
# Create the Master Table if it doesn't exist
con.execute("""
CREATE TABLE IF NOT EXISTS clean_trade (
flujo VARCHAR,
año INT,
mes INT,
fecha DATE,
cod_pais VARCHAR,
nombre_pais VARCHAR,
cod_provincia VARCHAR,
nombre_provincia VARCHAR,
cod_taric VARCHAR,
descripcion_taric VARCHAR,
euros DOUBLE,
dolares DOUBLE,
kilogramos DOUBLE,
source_file VARCHAR
)
""")
# Create a Log Table to remember processed files
con.execute("CREATE TABLE IF NOT EXISTS processed_log (filename VARCHAR, process_date TIMESTAMP)")
# Get list of already processed files
processed_files = set(row[0] for row in con.execute("SELECT filename FROM processed_log").fetchall())
print(f"📜 System remembers {len(processed_files)} previously processed files.")
# ---------------------------------------------------------
# 2. SCAN FOR NEW DATA (2015-2025+)
# ---------------------------------------------------------
# Look for year folders 20xx
year_folders = glob.glob(os.path.join(ROOT_PATH, "20*"))
candidate_files = []
for year_folder in year_folders:
# Get CSVs strictly inside the year folder (ignore subfolders like 'Trimestre')
files = glob.glob(os.path.join(year_folder, "*.csv"))
candidate_files.extend(files)
# Filter: Keep ONLY files we haven't seen yet
new_files = [f for f in candidate_files if fix_path(f) not in processed_files]
if not new_files:
print("✅ No new files found. Data is up to date.")
else:
print(f"⚡ Found {len(new_files)} NEW files. Starting incremental processing...")
# ---------------------------------------------------------
# 3. PROCESS NEW FILES (Incremental Batch)
# ---------------------------------------------------------
# Load Catalogs (Only needed if we have new files to process)
p_paises = fix_path(os.path.join(CATALOG_PATH, "PAISES.csv"))
p_sectores = fix_path(os.path.join(CATALOG_PATH, "SECTORES.csv"))
p_taric = fix_path(os.path.join(CATALOG_PATH, "TARIC.csv"))
p_provincias = fix_path(os.path.join(CATALOG_PATH, "PROVINCIAS.csv"))
con.execute(f"""
CREATE OR REPLACE TABLE paises AS SELECT * FROM read_csv('{p_paises}', delim='\\t', encoding='UTF-16', header=True, ignore_errors=True);
CREATE OR REPLACE TABLE sectores AS SELECT * FROM read_csv('{p_sectores}', delim='\\t', encoding='UTF-16', header=True, types={{'cod_sec': 'VARCHAR'}});
CREATE OR REPLACE TABLE taric_cat AS SELECT * FROM read_csv('{p_taric}', delim='\\t', encoding='UTF-16', header=True, types={{'cod_taric': 'VARCHAR'}});
CREATE OR REPLACE TABLE provincias AS SELECT * FROM read_csv('{p_provincias}', delim='\\t', encoding='UTF-16', header=True, types={{'cod_provincia': 'VARCHAR'}});
""")
# Sanitize paths for SQL
clean_paths = [fix_path(f) for f in new_files]
files_sql = "[" + ", ".join([f"'{f}'" for f in clean_paths]) + "]"
# ---------------------------------------------------------
# A. Robust Load (Smart Encoding Detection)
# ---------------------------------------------------------
print("⏳ Reading CSVs with auto-recovery (Mixed Encodings)...")
# 1. Create the Staging Table structure first (Empty)
# We perform a dummy read of the first file just to get the columns/types
first_file = clean_paths[0]
con.execute(f"""
CREATE OR REPLACE TABLE staging_raw AS
SELECT * FROM read_csv('{first_file}',
delim='\\t',
encoding='UTF-16',
header=True,
filename=True,
types={{'cod_taric': 'VARCHAR', 'pais': 'VARCHAR', 'provincia': 'VARCHAR'}}
) LIMIT 0;
""")
# 2. Loop through every file and try to append it safely
success_count = 0
error_count = 0
for f in clean_paths:
try:
# Attempt 1: Try UTF-16 (Most common for your data)
con.execute(f"""
INSERT INTO staging_raw
SELECT * FROM read_csv('{f}',
delim='\\t',
encoding='UTF-16',
header=True,
filename=True,
types={{'cod_taric': 'VARCHAR', 'pais': 'VARCHAR', 'provincia': 'VARCHAR'}}
)
""")
success_count += 1
except Exception as e:
# If UTF-16 fails, the file is likely UTF-8 or Latin-1
print(f"⚠️ UTF-16 failed for {os.path.basename(f)}. Retrying with Latin-1/Auto...")
try:
# Attempt 2: Let DuckDB Auto-Detect (Handles UTF-8/Latin-1)
con.execute(f"""
INSERT INTO staging_raw
SELECT * FROM read_csv('{f}',
delim='\\t',
auto_detect=True, -- Let DuckDB figure it out
header=True,
filename=True,
types={{'cod_taric': 'VARCHAR', 'pais': 'VARCHAR', 'provincia': 'VARCHAR'}}
)
""")
print(f" ✅ Recovered {os.path.basename(f)} using Auto-Detect.")
success_count += 1
except Exception as e2:
print(f"❌ FAILED to read {os.path.basename(f)}. Skipping.")
print(f" Error: {e2}")
error_count += 1
print(f"📦 Staging complete. Success: {success_count} | Failed: {error_count}")
# C. Update Log
print("📝 Updating history log...")
for f in clean_paths:
con.execute(f"INSERT INTO processed_log VALUES ('{f}', current_timestamp)")
# ---------------------------------------------------------
# 4. QUALITY CHECK (Corregido)
# ---------------------------------------------------------
print("\n🔍 --- DATA QUALITY REPORT ---")
# Check 1: Row count by Year
print("1. Rows per Year:")
# CORRECCIÓN: Usamos .df() para convertir a Pandas y luego imprimir
df_yearly = con.execute("SELECT año, count(*) as records, round(sum(euros)/1e9, 2) as billion_euros FROM clean_trade GROUP BY año ORDER BY año").df()
print(df_yearly)
# Check 2: Missing Countries?
print("\n2. Rows with Unknown Country (Should be 0):")
unknowns = con.execute("SELECT count(*) FROM clean_trade WHERE nombre_pais IS NULL").fetchone()[0]
print(f" -> {unknowns} rows")
# Check 3: Missing Products?
print("3. Rows with Unknown TARIC codes:")
unknown_taric = con.execute("SELECT count(*) FROM clean_trade WHERE descripcion_taric IS NULL").fetchone()[0]
print(f" -> {unknown_taric} rows")
# ---------------------------------------------------------
# 5. EXPORT CONSOLIDATED FILE
# ---------------------------------------------------------
# Only export if we added new files OR if the file doesn't exist
if new_files or not os.path.exists(FINAL_OUTPUT):
print(f"\n💾 Writing FULL consolidated history to {FINAL_OUTPUT}...")
# Overwrite the big file with the latest master data
con.execute(f"COPY clean_trade TO '{FINAL_OUTPUT}' (FORMAT PARQUET)")
print("✅ Consolidated File Updated.")
else:
print("\n⏩ No new data, skipping export to save time.")
con.close()
if __name__ == "__main__":
run_production_pipeline()

